Thinking в цифрах
Всего параметров
1T
Архитектура Mixture‑of‑Experts
Активные параметры
32B
Эффективный подсчёт на токен
Контекстное окно
256K
Обрабатывает целые исследовательские статьи
HLE Score
51.0
Точность рассуждений в heavy‑mode
Чем Thinking отличается
Kimi K2 Thinking не просто генерирует ответы — он рассуждает пошагово и показывает ход мысли, как человеческий эксперт
Пошаговое рассуждение
Смотрите, как модель разбивает сложные задачи на логические шаги. Kimi K2 Thinking показывает ход мысли, делая ответы прозрачными и проверяемыми — идеально для обучения и критически важных задач.
Продвинутая оркестрация инструментов
Выполняйте 200–300 последовательных вызовов инструментов без деградации качества. Цепочки API, обработка пайплайнов данных или координация систем — Thinking mode делает это точно и надёжно.
Нативная INT4‑квантование
Ускорение 2x с INT4 weight‑only квантованием MoE‑компонентов. QAT в пост‑тренинге обеспечивает нулевую потерю точности — все бенчмарки рассчитаны в INT4‑точности.
Создано для исследователей и инженеров
От академических исследований до production‑систем — Thinking mode даёт результат там, где важна точность
Математические рассуждения
Решает задачи уровня олимпиад с 100% точностью на AIME25. От абстрактной алгебры до продвинутого анализа — Thinking mode даёт строгие доказательства и ясные объяснения.
Анализ исследований
Обрабатывает научные статьи, синтезирует выводы и выявляет паттерны по сотням источников. Контекст 256K позволяет делать полноценные обзоры литературы в одном диалоге.
Frontend‑разработка
Заметный прогресс в HTML, React и задачах с большим количеством компонентов — превращайте идеи в полноценные адаптивные продукты. Создавайте сложные UI по одному промпту с высокой точностью.
Agentic Search‑задачи
Скор 60.2 на BrowseComp — лучший среди open‑моделей. Thinking mode автономно исследует источники, проверяет данные и синтезирует выводы.
Бенчмарк‑производительность
Kimi K2 Thinking показывает SOTA‑результаты в оценках, ориентированных на рассуждение
HLE: 51.0 (Heavy)
Humanity's Last Exam охватывает экспертные вопросы по 100+ предметам. K2 Thinking достигает 44.9% с инструментами и 51.0% в heavy‑mode — с параллельными траекториями рассуждений для самых сложных задач.
AIME25: 100.0
Задачи American Invitational Mathematics Examination. 100% точность с Python‑инструментами, решая конкуретные задачи уровня олимпиад.
BrowseComp: 60.2
Agentic web search и синтез информации. Скор 60.2 — лучший среди open‑source моделей — демонстрирует сильные автономные исследовательские навыки.
SWE-Bench Verified: 71.3%
Реальные задачи инженерии ПО из GitHub issues. 71.3% точности на проверенных задачах — производственная готовность, превосходящая отраслевые бенчмарки.
Технические особенности
Что важно знать разработчикам и исследователям
Mixture‑of‑Experts архитектура
384 специализированных эксперта, по 8 на токен. Это даёт триллионную мощность, активируя лишь 32B параметров на один вывод — оптимальный баланс возможностей и эффективности.
Multi-head Latent Attention (MLA)
Продвинутый механизм внимания, повышающий когерентность рассуждений на длинном контексте. MLA улучшает понимание сложных взаимосвязей в больших документах.
Совместимость с OpenAI и Anthropic
Drop‑in замена для существующих интеграций. Тот же формат API, те же параметры — просто направьте код на Kimi K2 endpoints и получите лучшую производительность.
Несколько inference‑движков
Развёртывайте с vLLM, SGLang или KTransformers. Выберите движок под вашу инфраструктуру — все оптимизированы под архитектуру Kimi K2 Thinking.
Open Source под лицензией MIT
Полные веса модели доступны для исследований и коммерческого использования. Modified MIT License позволяет развёртывать Thinking mode где угодно — от стартапов до enterprise.
Production‑ready API доступ
Доступно на kimi-k2.ai с прозрачной ценой и надёжностью уровня enterprise. Полная совместимость с OpenAI и Anthropic — просто поменяйте URL endpoints и используйте Kimi K2 Thinking.
Ключевые показатели
K2 Thinking достигает SOTA‑результатов в рассуждении, кодинге и agentic‑задачах
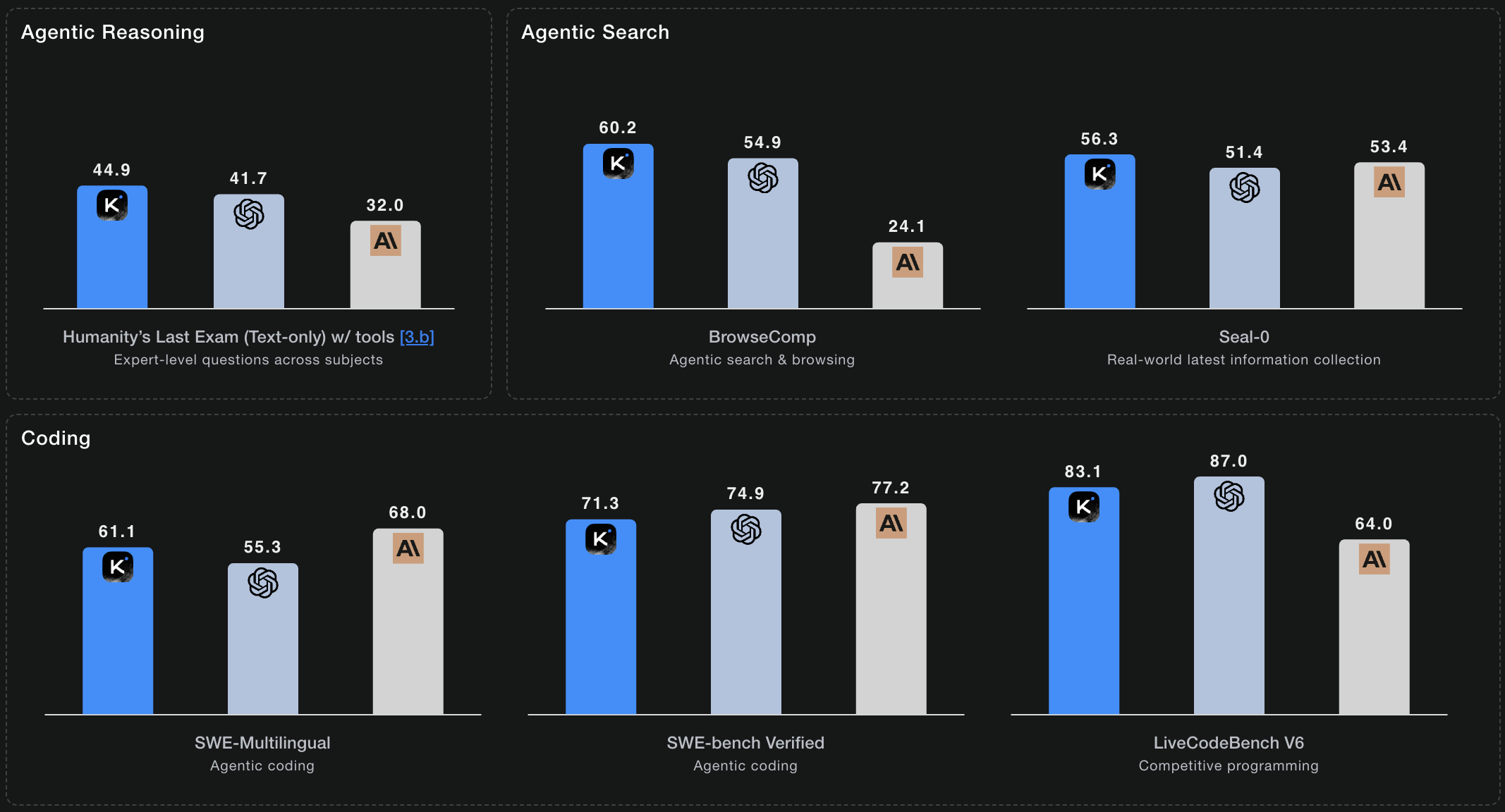
* Бенчмарки из официальной техдокументации Kimi K2 Thinking
Часто задаваемые вопросы
Всё, что нужно знать о Kimi K2 Thinking
Чем Thinking mode отличается от стандартного Kimi K2?
Thinking mode специализируется на многошаговом рассуждении и показывает ход мысли. Стандартный Kimi K2 хорош для широких задач, а Thinking mode оптимизирован для глубокой логики — математические доказательства, исследовательские синтезы, сложный дебаг. Это разница между быстрым ответом и подробным решением с доказательством.
Сколько стоит Thinking mode?
На kimi-k2.ai — прозрачная, конкурентная цена. Начните с бесплатных кредитов, затем выберите pay‑as‑you‑go или подписку, масштабируемую под ваши нужды. Также доступен self‑hosting с open‑source весами под Modified MIT License.
Можно ли запускать Thinking mode на своих серверах?
Да. Полные веса доступны по Modified MIT License. Разворачивайте через vLLM, SGLang или KTransformers на своей инфраструктуре. Требования к железу зависят от пропускной способности и использования INT4 квантования.
Как работает оркестрация инструментов?
Thinking mode может цепочкой выполнять 200–300 последовательных вызовов инструментов — API‑запросы, запросы к БД, операции с файлами — без потери контекста. Он планирует весь процесс, корректно обрабатывает ошибки и адаптируется по промежуточным результатам.
Какова реальная производительность в кодинге?
Kimi K2 Thinking достигает 100% точности на задачах AIME25 при использовании Python‑инструментов. Пошаговый подход особенно эффективен для сложных паттернов, edge cases и написания устойчивых реализаций.
Подходит ли Thinking mode для production?
Да. Нативное INT4‑квантование даёт 2x ускорение, а инфраструктура уровня enterprise на kimi-k2.ai готова для продакшена с первого дня. Начните с hosted API (совместимость с OpenAI/Anthropic) или разверните open‑source веса на своих серверах.
Готовы думать глубже?
Оцените следующее поколение рассуждающего AI. Начните решать сложные задачи с Kimi K2 Thinking уже сегодня.