Thinking in Numbers
Total Parameters
1T
Mixture-of-Experts architecture
Active Parameters
32B
Efficient per-token computation
Context Window
256K
Process entire research papers
HLE Score
51.0
Heavy-mode reasoning accuracy
What Makes Thinking Different
Kimi K2 Thinking doesn't just generate answers—it reasons through problems step by step, showing its work like a human expert
Step-by-Step Reasoning
Watch the model break down complex problems into logical steps. Kimi K2 Thinking shows its thought process, making every answer transparent and verifiable—perfect for educational contexts and critical applications.
Advanced Tool Orchestration
Execute 200-300 sequential tool calls without degradation. Whether it's chaining API requests, processing data pipelines, or coordinating multiple systems, Thinking mode handles it with precision.
Native INT4 Quantization
Achieve 2x speed-up with INT4 weight-only quantization applied to MoE components. Quantization-aware training (QAT) during post-training ensures zero accuracy loss—all benchmark results use INT4 precision.
Built for Researchers and Engineers
From academic research to production systems, Thinking mode delivers results where precision matters
Mathematical Reasoning
Solve competition-level math problems with 100% accuracy on AIME25 challenges. From abstract algebra to advanced calculus, Thinking mode provides rigorous proofs and clear explanations.
Research Analysis
Process academic papers, synthesize findings, and identify patterns across hundreds of sources. The 256K context window handles entire literature reviews in a single conversation.
Frontend Development
Notable improvements on HTML, React, and component-intensive tasks—translate ideas into fully functional, responsive products. Build complex UIs from a single prompt with precision and adaptability.
Agentic Search Tasks
Score 60.2 on BrowseComp benchmarks—the highest among open models. Thinking mode autonomously navigates information spaces, verifies sources, and synthesizes insights.
Benchmark Performance
Kimi K2 Thinking achieves state-of-the-art results across reasoning-focused evaluations
HLE: 51.0 (Heavy)
Humanity's Last Exam covers expert-level questions across 100+ subjects. K2 Thinking achieves 44.9% with tools and 51.0% in heavy mode—using parallel reasoning trajectories for the most demanding problems.
AIME25: 100.0
American Invitational Mathematics Examination problems. Achieves perfect 100% accuracy with Python tools, solving competition-level mathematics that challenges even expert mathematicians.
BrowseComp: 60.2
Agentic web search and information synthesis. Scores 60.2 - the highest among open-source models - showcasing exceptional autonomous research capabilities.
SWE-Bench Verified: 71.3%
Real-world software engineering tasks from GitHub issues. Achieves 71.3% accuracy on verified problems, demonstrating production-ready coding capabilities that surpass industry benchmarks.
Technical Features
What developers and researchers need to know
Mixture-of-Experts Architecture
384 specialized experts with 8 selected per token. This approach delivers trillion-parameter intelligence while activating only 32 billion parameters per inference—optimal balance of capability and efficiency.
Multi-head Latent Attention (MLA)
Advanced attention mechanism that improves reasoning coherence across long contexts. MLA enables better understanding of complex relationships in massive documents.
OpenAI & Anthropic Compatible
Drop-in replacement for existing integrations. Same API format, same parameters—just point your existing code to Kimi K2 endpoints and watch performance improve.
Multiple Inference Engines
Deploy with vLLM, SGLang, or KTransformers. Choose the engine that fits your infrastructure—all optimized for Kimi K2 Thinking's unique architecture.
Open Source Under MIT License
Full model weights available for research and commercial use. Modified MIT License ensures you can deploy Thinking mode anywhere, from startups to enterprises.
Production-Ready API Access
Available on kimi-k2.ai with transparent pricing and enterprise-grade reliability. Drop-in compatible with OpenAI and Anthropic APIs—just change the endpoint URL to start using Kimi K2 Thinking.
Performance Highlights
K2 Thinking achieves state-of-the-art performance across reasoning, coding, and agentic tasks
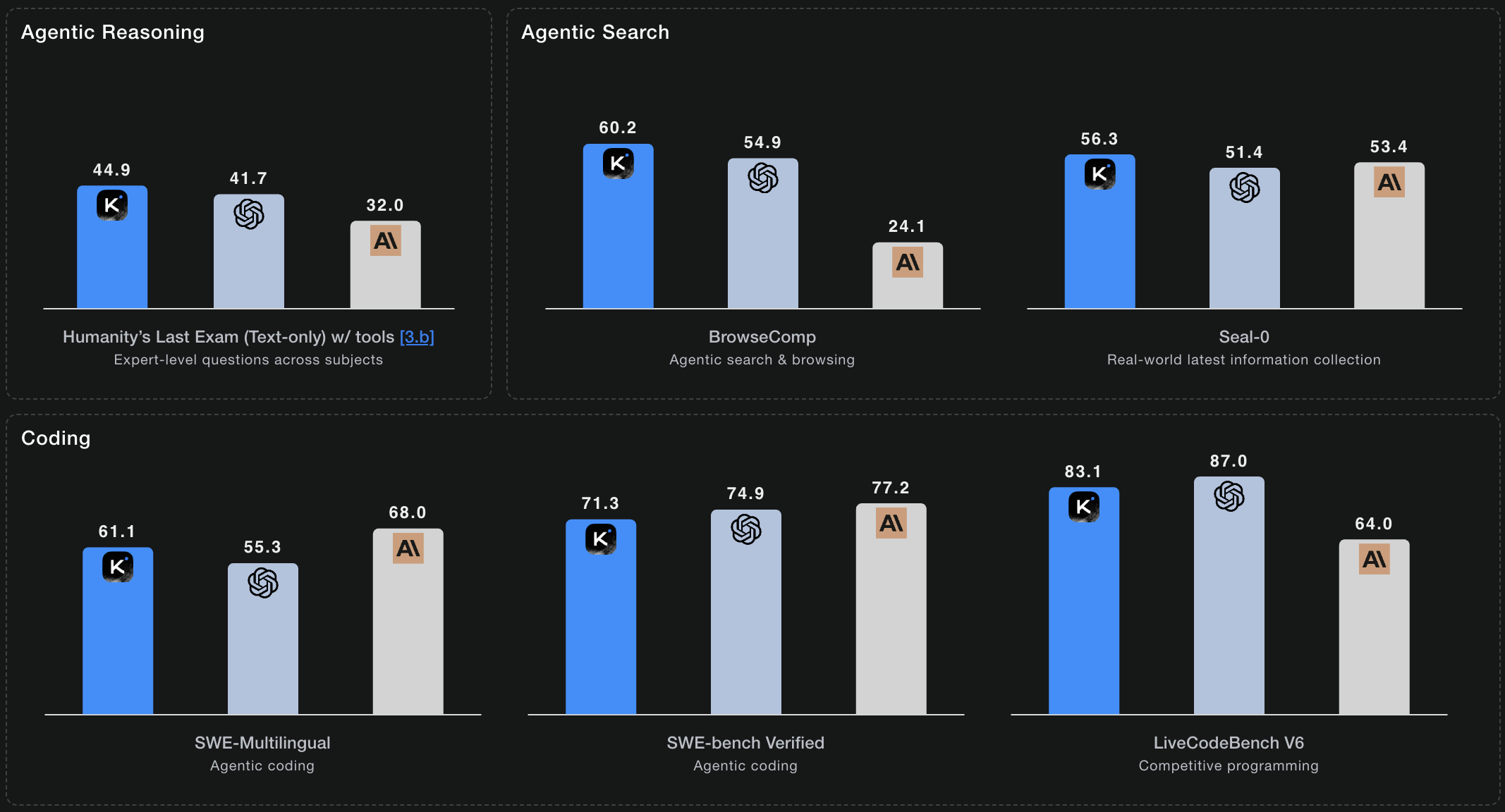
* Benchmarks from official Kimi K2 Thinking technical documentation
Frequently Asked Questions
Everything you need to know about Kimi K2 Thinking
How is Thinking mode different from standard Kimi K2?
Thinking mode specializes in multi-step reasoning and shows its work. While standard Kimi K2 excels at general tasks, Thinking mode is optimized for problems requiring deep logical analysis—mathematical proofs, research synthesis, complex debugging. It's like the difference between a quick answer and a detailed solution with proof.
What's the cost for using Thinking mode?
We offer transparent, competitive pricing at kimi-k2.ai. Start with free credits to test the model, then choose from flexible pay-as-you-go or subscription plans that scale with your needs. Self-hosting is also available with open-source weights under Modified MIT License.
Can I run Thinking mode on my own servers?
Yes. Full model weights are available under Modified MIT License. Deploy with vLLM, SGLang, or KTransformers inference engines on your own infrastructure. Hardware requirements depend on your throughput needs and whether you use INT4 quantization.
How does tool orchestration work?
Thinking mode can chain 200-300 sequential tool calls—API requests, database queries, file operations—without losing context. It plans the entire workflow, handles errors gracefully, and adapts based on intermediate results. Perfect for building agentic systems that need to coordinate multiple services.
What's the real-world performance on coding tasks?
Kimi K2 Thinking achieves 100% accuracy on AIME25 mathematical problems when using Python tools. The step-by-step reasoning approach makes it particularly effective at understanding complex code patterns, edge cases, and writing robust implementations.
Is Thinking mode suitable for production?
Absolutely. With native INT4 quantization for 2x speed-up and enterprise-grade infrastructure at kimi-k2.ai, it's production-ready from day one. Get started with our hosted API featuring OpenAI/Anthropic compatibility, or deploy the open-source weights on your own servers.
Ready to Think Deeper?
Experience the next generation of reasoning AI. Start solving complex problems with Kimi K2 Thinking today.