संख्याओं में Thinking
कुल पैरामीटर
1T
Mixture‑of‑Experts आर्किटेक्चर
सक्रिय पैरामीटर
32B
प्रति‑टोकन कुशल कम्प्यूट
कॉन्टेक्स्ट विंडो
256K
पूरे रिसर्च पेपर प्रोसेस करें
HLE स्कोर
51.0
Heavy‑mode रीजनिंग सटीकता
Thinking को अलग क्या बनाता है
Kimi K2 Thinking सिर्फ उत्तर नहीं देता—वह समस्याओं को चरण‑दर‑चरण तर्क के साथ सुलझाता है, बिल्कुल मानव विशेषज्ञ की तरह
चरण‑दर‑चरण रीजनिंग
देखें मॉडल जटिल समस्याओं को तार्किक चरणों में कैसे तोड़ता है। Kimi K2 Thinking अपना विचार‑प्रक्रिया दिखाता है, जिससे हर उत्तर पारदर्शी और सत्यापित बनता है—शिक्षा और क्रिटिकल एप्लिकेशन के लिए परफेक्ट।
एडवांस्ड टूल ऑर्केस्ट्रेशन
200‑300 क्रमिक टूल कॉल बिना गुणवत्ता गिरावट के चलाएँ। चाहे API चेनिंग, डेटा पाइपलाइन प्रोसेसिंग या मल्टी‑सिस्टम कोऑर्डिनेशन हो, Thinking मोड इसे सटीकता से संभालता है।
नेटिव INT4 क्वांटाइज़ेशन
MoE कंपोनेंट्स पर INT4 वेट‑ओनली क्वांटाइज़ेशन से 2x स्पीड‑अप। पोस्ट‑ट्रेनिंग में क्वांटाइज़ेशन‑अवेयर ट्रेनिंग (QAT) से शून्य सटीकता हानि—सभी बेंचमार्क INT4 प्रिसीजन पर हैं।
रिसर्चर्स और इंजीनियर्स के लिए बनाया गया
एकेडमिक रिसर्च से लेकर प्रोडक्शन सिस्टम तक, Thinking मोड वहाँ परिणाम देता है जहाँ सटीकता मायने रखती है
गणितीय रीजनिंग
AIME25 जैसी प्रतियोगिता‑स्तरीय समस्याओं में 100% सटीकता। एब्स्ट्रैक्ट एल्जेब्रा से एडवांस्ड कैलकुलस तक, Thinking मोड कठोर प्रमाण और स्पष्ट व्याख्या देता है।
रिसर्च विश्लेषण
अकादमिक पेपर्स प्रोसेस करें, निष्कर्षों का सार निकालें, और सैकड़ों स्रोतों में पैटर्न पहचानें। 256K कॉन्टेक्स्ट विंडो पूरी लिटरेचर रिव्यू को एक बातचीत में संभालती है।
फ्रंटएंड डेवलपमेंट
HTML, React और कंपोनेंट‑इंटेंसिव कार्यों में उल्लेखनीय सुधार—आइडियाज को पूरी तरह कार्यात्मक, रिस्पॉन्सिव प्रोडक्ट्स में बदलें। एक ही प्रॉम्प्ट से जटिल UI बनाएँ, सटीकता और अनुकूलनशीलता के साथ।
एजेंटिक सर्च टास्क
BrowseComp बेंचमार्क पर 60.2 स्कोर—ओपन मॉडलों में सबसे ऊँचा। Thinking मोड स्वायत्त रूप से सूचना‑क्षेत्रों में नेविगेट करता है, स्रोतों की पुष्टि करता है और इनसाइट्स सिंथेसाइज़ करता है।
बेंचमार्क प्रदर्शन
Kimi K2 Thinking रीजनिंग‑केंद्रित मूल्यांकन में स्टेट‑ऑफ‑द‑आर्ट परिणाम देता है
HLE: 51.0 (Heavy)
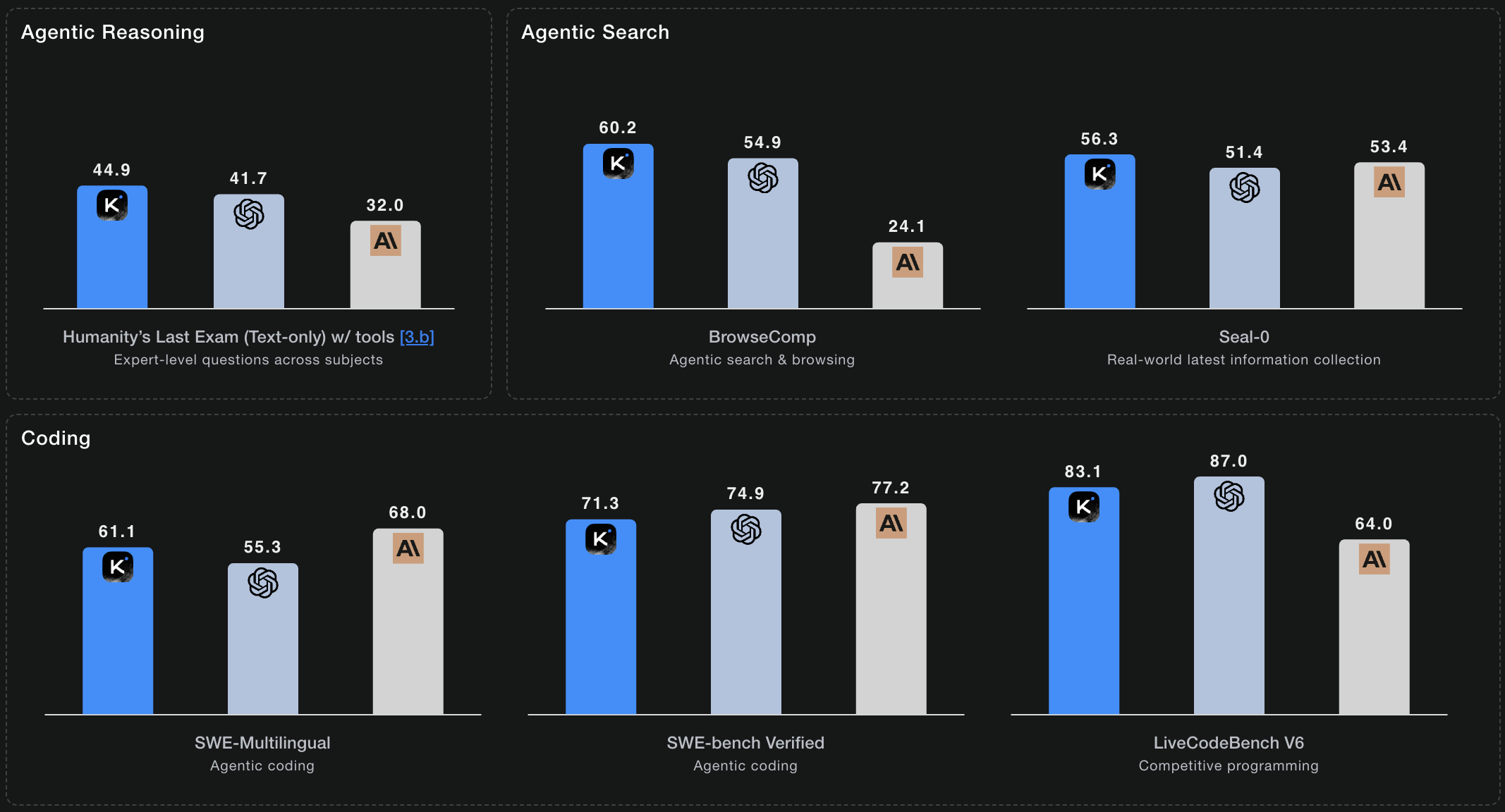
Humanity's Last Exam 100+ विषयों में विशेषज्ञ‑स्तरीय प्रश्न कवर करता है। K2 Thinking टूल्स के साथ 44.9% और heavy मोड में 51.0% हासिल करता है—सबसे कठिन समस्याओं के लिए parallel reasoning trajectories का उपयोग करके।
AIME25: 100.0
American Invitational Mathematics Examination समस्याएँ। Python टूल्स के साथ 100% सटीकता प्राप्त करता है, ऐसे प्रतियोगिता‑स्तर के गणित को हल करता है जो विशेषज्ञ गणितज्ञों के लिए भी चुनौतीपूर्ण हैं।
BrowseComp: 60.2
एजेंटिक वेब सर्च और सूचना सिंथेसिस। 60.2 स्कोर—ओपन‑सोर्स मॉडलों में सबसे उच्च—स्वायत्त रिसर्च क्षमताओं को दर्शाता है।
SWE-Bench Verified: 71.3%
GitHub इश्यूज़ से वास्तविक सॉफ्टवेयर इंजीनियरिंग कार्य। सत्यापित समस्याओं पर 71.3% सटीकता, जो इंडस्ट्री बेंचमार्क से बेहतर प्रोडक्शन‑रेडी कोडिंग क्षमता दिखाता है।
टेक्निकल फीचर्स
डेवलपर्स और रिसर्चर्स को जो जानना चाहिए
Mixture‑of‑Experts आर्किटेक्चर
384 विशेषज्ञों में से प्रति टोकन 8 चयनित। यह तरीका ट्रिलियन‑पैरामीटर इंटेलिजेंस देता है जबकि प्रति इनफेरेंस केवल 32B पैरामीटर सक्रिय होते हैं—क्षमता और दक्षता का आदर्श संतुलन।
Multi-head Latent Attention (MLA)
एडवांस्ड अटेंशन मैकेनिज्म जो लंबे कॉन्टेक्स्ट में रीजनिंग को बेहतर बनाता है। MLA विशाल दस्तावेज़ों में जटिल संबंधों की बेहतर समझ सक्षम करता है।
OpenAI और Anthropic Compatible
मौजूदा इंटीग्रेशन के लिए ड्रॉप‑इन रिप्लेसमेंट। वही API फ़ॉर्मेट, वही पैरामीटर—बस अपने कोड को Kimi K2 एंडपॉइंट्स पर पॉइंट करें और बेहतर प्रदर्शन देखें।
Multiple Inference Engines
vLLM, SGLang या KTransformers के साथ डिप्लॉय करें। अपनी इंफ्रास्ट्रक्चर के अनुसार इंजन चुनें—सब Kimi K2 Thinking की विशेष आर्किटेक्चर के लिए ऑप्टिमाइज़्ड हैं।
MIT लाइसेंस के तहत ओपन सोर्स
फुल मॉडल वेट्स रिसर्च और कमर्शियल उपयोग के लिए उपलब्ध। Modified MIT License सुनिश्चित करता है कि आप Thinking मोड को कहीं भी डिप्लॉय कर सकते हैं—स्टार्टअप से एंटरप्राइज तक।
Production‑Ready API Access
kimi-k2.ai पर पारदर्शी प्राइसिंग और एंटरप्राइज‑ग्रेड विश्वसनीयता के साथ उपलब्ध। OpenAI और Anthropic APIs के साथ ड्रॉप‑इन कम्पैटिबल—बस endpoint URL बदलें और Kimi K2 Thinking उपयोग करना शुरू करें।
प्रदर्शन हाइलाइट्स
K2 Thinking रीजनिंग, कोडिंग और एजेंटिक टास्क्स में स्टेट‑ऑफ‑द‑आर्ट प्रदर्शन देता है
* बेंचमार्क आधिकारिक Kimi K2 Thinking तकनीकी डॉक्यूमेंटेशन से हैं
अक्सर पूछे जाने वाले प्रश्न
Kimi K2 Thinking के बारे में आपको जो जानना चाहिए
Thinking मोड मानक Kimi K2 से कैसे अलग है?
Thinking मोड बहु‑चरण रीजनिंग में विशेषज्ञ है और अपना काम दिखाता है। जहाँ मानक Kimi K2 सामान्य कार्यों में उत्कृष्ट है, वहीं Thinking मोड गहन तार्किक विश्लेषण वाली समस्याओं के लिए अनुकूलित है—गणितीय प्रमाण, रिसर्च सिंथेसिस, जटिल डिबगिंग। यह त्वरित उत्तर बनाम प्रमाण सहित विस्तृत समाधान जैसा है।
Thinking मोड का खर्च कितना है?
हम kimi-k2.ai पर पारदर्शी, प्रतिस्पर्धी प्राइसिंग देते हैं। मॉडल टेस्ट करने के लिए मुफ्त क्रेडिट से शुरू करें, फिर अपनी जरूरत के अनुसार pay‑as‑you‑go या सब्सक्रिप्शन प्लान चुनें। Modified MIT License के तहत ओपन‑सोर्स वेट्स के साथ self‑hosting भी उपलब्ध है।
क्या मैं Thinking मोड अपने सर्वर पर चला सकता हूँ?
हाँ। Modified MIT License के तहत पूर्ण मॉडल वेट्स उपलब्ध हैं। vLLM, SGLang या KTransformers इंफेरेंस इंजन के साथ अपने इंफ्रास्ट्रक्चर पर डिप्लॉय करें। हार्डवेयर आवश्यकताएँ आपके throughput और INT4 क्वांटाइज़ेशन पर निर्भर करती हैं।
टूल ऑर्केस्ट्रेशन कैसे काम करता है?
Thinking मोड 200‑300 क्रमिक टूल कॉल—API रिक्वेस्ट, डेटाबेस क्वेरी, फाइल ऑपरेशन—बिना कॉन्टेक्स्ट खोए चेन कर सकता है। यह पूरा वर्कफ़्लो प्लान करता है, त्रुटियों को ग्रेसफुली संभालता है और मध्यवर्ती परिणामों के आधार पर अनुकूलन करता है।
कोडिंग कार्यों पर वास्तविक प्रदर्शन कैसा है?
Kimi K2 Thinking Python टूल्स के साथ AIME25 गणितीय समस्याओं पर 100% सटीकता हासिल करता है। स्टेप‑बाय‑स्टेप रीजनिंग इसे जटिल कोड पैटर्न, edge cases और मजबूत इम्प्लीमेंटेशन समझने में खास प्रभावी बनाता है।
क्या Thinking मोड प्रोडक्शन के लिए उपयुक्त है?
बिल्कुल। नेटिव INT4 क्वांटाइज़ेशन से 2x स्पीड‑अप और kimi-k2.ai की एंटरप्राइज‑ग्रेड इंफ्रास्ट्रक्चर के साथ, यह day‑one पर प्रोडक्शन‑रेडी है। OpenAI/Anthropic कम्पैटिबल होस्टेड API के साथ शुरुआत करें, या ओपन‑सोर्स वेट्स को अपने सर्वर पर डिप्लॉय करें।
और गहराई से सोचने के लिए तैयार?
रीजनिंग AI की अगली पीढ़ी का अनुभव करें। आज ही Kimi K2 Thinking के साथ जटिल समस्याएँ हल करना शुरू करें।